* NL JOIN
- 프로그래밍에서 사용하는 중첩된 반복문과 유사한 방식으로 조인을 수행
- 반복문의 외부에 있는 테이블을 선행 또는 외부 테이블, 반복문의 내부에 있는 테이블을 후행 또는 내부 테이블
FOR 선행 테이블 읽음 → 외부 테이블(Outer Table)
FOR 후행 테이블 읽음 → 내부 테이블(Inner Table) (선행 테이블과 후행 테이블 조인)① 선행 테이블에서 주어진 조건을 만족하는 행을 찾음
② 선행 테이블의 조인 키 값을 가지고 후행 테이블에서 조인 수행
③ 선행 테이블의 조건을 만족하는 모든 행에 대해 1번 작업 반복 수행
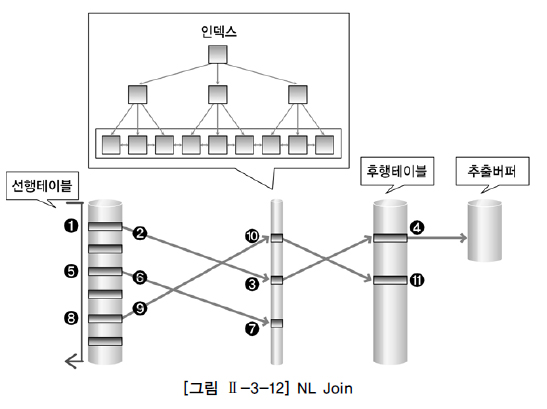
① 선행 테이블에서 조건을 만족하는 첫 번째 행을 찾음
→ 이때 선행 테이블에 주어진 조건을 만족하지 않는 경우 해당 데이터는 필터링 됨
② 선행 테이블의 조인 키를 가지고 후행 테이블에 조인 키가 존재하는지 찾으러 감 → 조인 시도
③ 후행 테이블의 인덱스에 선행 테이블의 조인 키가 존재하는지 확인
→ 선행 테이블의 조인 값이 후행 테이블에 존재하지 않으면 선행 테이블 데이터는 필터링 됨
(더 이상 조인 작업을 진행할 필요 없음)
④ 인덱스에서 추출한 레코드 식별자를 이용하여 후행 테이블을 액세스
→ 인덱스 스캔을 통한 테이블 액세스 후행 테이블에 주어진 조건까지 모두 만족하면 해당 행을 추출버퍼에 넣음
⑤ ~ ⑪ 앞의 작업을 반복 수행함
* SORT MERGE JOIN
- 조인 칼럼을 기준으로 데이터를 정렬하여 조인을 수행
- Sort Merge Join은 주로 스캔 방식으로 데이터를 읽음
- Sort Merge Join은 랜덤 액세스로 NL Join에서 부담이 되던 넓은 범위의 데이터를 처리할 때 이용되던 조인 기법
- Sort Merge Join은 Hash Join과는 달리 동등 조인 뿐만 아니라 비동등 조인에 대해서도 조인 작업이 가능하다는 장점

① 선행 테이블에서 주어진 조건을 만족하는 행을 찾음
② 선행 테이블의 조인 키를 기준으로 정렬 작업을 수행
① ~ ②번 작업을 선행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행
③ 후행 테이블에서 주어진 조건을 만족하는 행을 찾음
④ 후행 테이블의 조인 키를 기준으로 정렬 작업을 수행
③ ~ ④번 작업을 후행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행
⑤ 정렬된 결과를 이용하여 조인을 수행하며 조인에 성공하면 추출버퍼에 넣음
* HASH JOIN

① 선행 테이블에서 주어진 조건을 만족하는 행을 찾음
② 선행 테이블의 조인 키를 기준으로 해쉬 함수를 적용하여 해쉬 테이블을 생성
→ 조인 칼럼과 SELECT 절에서 필요로 하는 칼럼도 함께 저장됨
① ~ ②번 작업을 선행 테이블의 조건을 만족하는 모든 행에 대해 반복 수행
③ 후행 테이블에서 주어진 조건을 만족하는 행을 찾음
④ 후행 테이블의 조인 키를 기준으로 해쉬 함수를 적용하여 해당 버킷을 찾음
→ 조인 키를 이용해서 실제 조인될 데이터를 찾음
⑤ 조인에 성공하면 추출버퍼에 넣음
③ ~ ⑤번 작업을 후행 테이블의 조건을 만족하는 모든 행에 대해서 반복 수행
- 조인 칼럼의 인덱스를 사용하지 않기 때문에 조인 칼럼의 인덱스가 존재하지 않을 경우에도 사용할 수 있는 조인 기법
- 해쉬 함수를 적용한 값은 어떤 값으로 해슁될 지 모름. 해쉬 함수 적용 시 동일한 값은 항상 같은 값으로 해슁됨
- 생성된 해쉬 테이블의 크기가 메모리에 적재할 수 있는 크기보다 더 커지면 임시 영역(디스크)에 해쉬 테이블을 저장
- 선행 테이블을 Build Input이라고도 하며,
후행 테이블은 만들어진 해쉬 테이블에 대해 해쉬 값의 존재여부를 검사한다고 해서 Prove Input
'SQLD' 카테고리의 다른 글
| [SQLD 암기] 데이터 모델과 성능 (0) | 2020.09.01 |
|---|---|
| [SQLD 암기] 데이터 모델링의 이해 (0) | 2020.08.31 |
| [SQLD : Ⅴ. SQL 최적화 기본 원리] 2. 인덱스 기본 (0) | 2020.08.22 |
| [SQLD : Ⅴ. SQL 최적화 기본 원리] 1. 옵티마이저와 실행계획 (0) | 2020.08.22 |
| [SQLD : Ⅳ. SQL 활용] 8-2. 절차형 SQL (0) | 2020.08.22 |

