* 정규화를 통한 성능 향상 전략
- 데이터에 대한 중복성을 제거, 데이터를 관심사별로 처리
- 정규화는 데이터를 결정하는 결정자에 의해 함수적 종속을 갖고 있는 일반속성을 입력,수정,삭제 이상을 제거
- 데이터 용량이 최소화되는 효과

* 반정규화된 테이블의 성능저하 사례
1) 조인을 하더라도 PK unique index를 이용하면 조인 성능 저하는 미미하게 발생
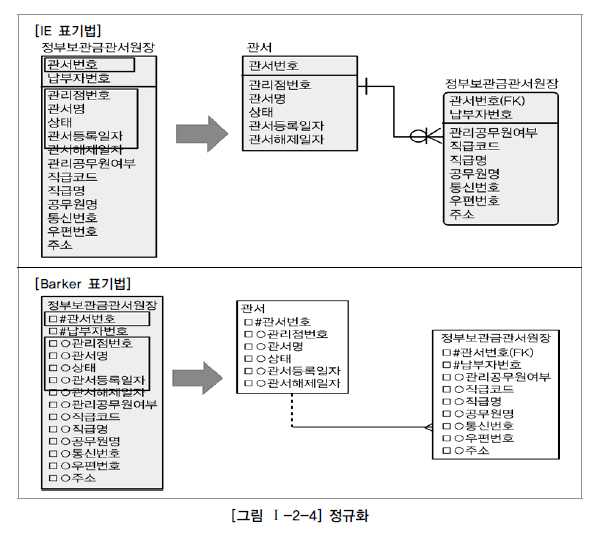
- 오른쪽은 왼쪽을 부분키 종속을 정규화하여 2차 정규화한 테이블
- PK가 걸려있는 방향으로 조인이 걸려 unique index를 곧바로 찾아서 데이터를 조회
2) 함수적 종속관계 형성
- 매각일자 5천 건, 일자별매각물건은 100만 건이 있다고 가정
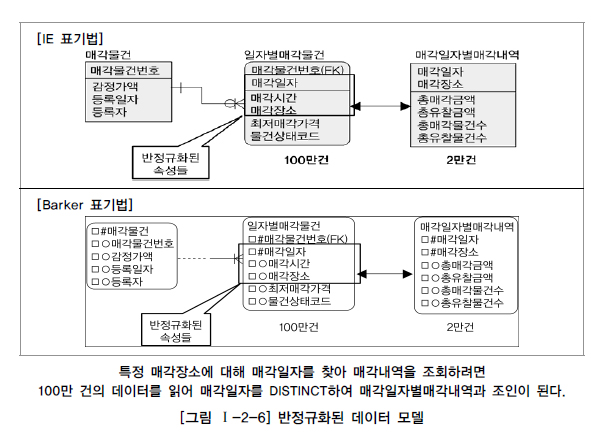
- 서울7호 에서 매각된 총매각금액, 총유찰금액을 산출하는 조회용 SQL문장은
SELECT B.총매각금액 , B.총유찰금액
FROM (SELECT DISTINCT 매각일자
FROM 일자별매각물건
WHERE 매각장소 = '서울 7호') A,
<== 100만건의 데이터를 읽어 DISTINCT함 매각일자별매각내역 B
WHERE A.매각일자 = B.매각일자 AND A.매각장소 = B.매각장소;- 대량 데이터에서 조인 조건이 되는 대상을 찾기 위해 인라인뷰를 사용하기 때문에 성능이 저하됨
- 복합식별자 중 일반속성이 주식별자 속성 중 일부에만 종속관계를 갖고 있으므로 2차 정규화의 대상이 됨

- 2차 정규화로 매각일자를 PK로 하고 매각시간과 매각장소는 일반속성이 됨
- 매각일자를 PK로 사용하는 매각일자별매각내역과도 관계가 연결됨
- 이 때 서울7호에서 매각된 총매각금액, 총유찰금액을 산출하는 조회용 SQL문은
SELECT B.총매각금액 , B.총유찰금액
FROM 매각기일 A, 매각일자별매각내역 B
WHERE A.매각장소 = '서울 7호' <== 5천건의 데이터를 읽음
AND A.매각일자 = B.매각일자
AND A.매각장소 = B.매각장소;- 매각기일 테이블이 정규화되면서 드라이빙 되는 대상 테이블의 데이터가 5천 건으로 줄어들어 조회처리가 빨리됨
3) 동일한 속성 형식을 두 개 이상의 속성으로 나열하여 반정규화한 경우
- 계층형 데이터베이스를 많이 사용했던 과거 데이터 모델링의 습관이 남아서
관계형 데이터베이스에도 동일한 속성을 한 테이블에 모델링하는 경우가 많음
- 데이터는 30만 건이고 온라인 환경의 데이터베이스라고 가정
인덱스 생성 시 유형기능분류코드를 각각에 대해 인덱스를 생성해야 하여 9개의 인덱스 추가생성 해야함
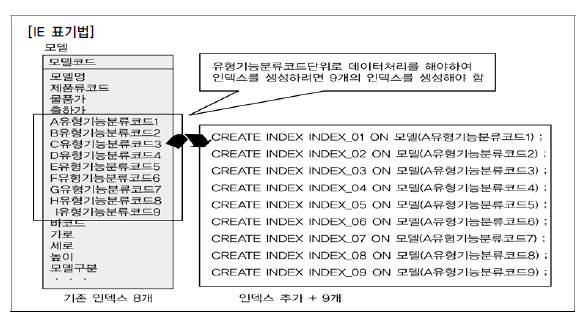
- 각 유형코드별로 조건을 부여하여 모델코드와 모델명을 조회하는 SQL문장
SELECT 모델코드, 모델명
FROM 모델
WHERE ( A유형기능분류코드1 = '01' )
OR ( B유형기능분류코드2 = '02' )
OR ( C유형기능분류코드3 = '07' )
OR ( D유형기능분류코드4 = '01' )
OR ( E유형기능분류코드5 = '02' )
OR ( F유형기능분류코드6 = '07' )
OR ( G유형기능분류코드7 = '03' )
OR ( H유형기능분류코드8 = '09' )
OR ( I유형기능분류코드9 = '09' )- 각 유형별로 모두 인덱스가 걸려 있어야 인덱스에 의해 데이터를 찾을 수 있음

- 정규화되어 분리된 이후 인덱스 추가 생성은 0개,
- 분리된 테이블 모델기능분류코드에서 PK 인덱스를 생성하여 이용함으로써 성능 향상
- 각 유형코드별로 조건을 부여하여 모델코드와 모델명을 조회하는 SQL문장
SELECT A.모델코드, A.모델명
FROM 모델 A, 모델기능분류코드 B
WHERE ( B.유형코드 = 'A' AND B.기능분류코드 = '01' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'B' AND B.기능분류코드 = '02' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'C' AND B.기능분류코드 = '07' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'D' AND B.기능분류코드 = '01' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'E' AND B.기능분류코드 = '02' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'F' AND B.기능분류코드 = '07' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'G' AND B.기능분류코드 = '03' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'H' AND B.기능분류코드 = '09' AND A.모델코드 = B.모델코드 )
OR ( B.유형코드 = 'I' AND B.기능분류코드 = '09' AND A.모델코드 = B.모델코드 )- 유형코드+기능분류코드+모델코드에 인덱스가 걸려 있으므로 인덱스를 통해 데이터를 조회함으로써 성능향상
4) 일재고와 일재고 상세를 구분하여 일재고에 발생되는 트랜잭션의 성능 저하 예방

* 함수적 종속성에 근거한 정규화 수행 필요
- 함수적 종속성은 데이터들이 어떤 기준값에 의해 종속되는 현상을 지칭
- 기준값을 결정자라 하고 종속되는 값을 종속자라고 함

- 사람이라는 엔티티는 주민등록번호, 이름, 출생지, 호주 속성 존재
- 출생지, 호주 속성은 주민등록번호 속성에 종속, 주민등록번호 신고되면 이름, 출생지, 호주가 생성되어 하나의 값
(주민등록번호 -> (이름, 출생지, 호주))
- 함수의 종속성은 데이터가 갖는 근본적인 속성으로 인식되고 있음
- 정규화의 궁극적인 목적은 반복적인 데이터를 분리하고 각 데이터가 종속된 테이블에 적절하게 배치되도록 하는 것
= 데이터의 정합성이 지켜지는 것
- 데이터는 속성 간의 함수 종속성에 근거하여 정규화 되어야 함
'SQLD' 카테고리의 다른 글
| [SQLD : Ⅱ. 데이터 모델과 성능] 4. 대량 데이터에 따른 성능 (0) | 2020.08.13 |
|---|---|
| [SQLD : Ⅱ. 데이터 모델과 성능] 3. 반정규화와 성능 (0) | 2020.08.11 |
| [SQLD : Ⅱ. 데이터 모델과 성능] 1. 성능 데이터 모델링의 개요 (0) | 2020.08.11 |
| [SQLD : Ⅰ. 데이터 모델링의 이해] 5-3. ERD, 데이터 모델의 요소 (0) | 2020.08.11 |
| [SQLD : Ⅰ. 데이터 모델링의 이해] 5-2. 데이터 모델링 (0) | 2020.08.11 |



